І. Перевірка знань набутих на попередньому уроці:
Пройдіть тестування (тест відкритий до 21.01.21 23-00)
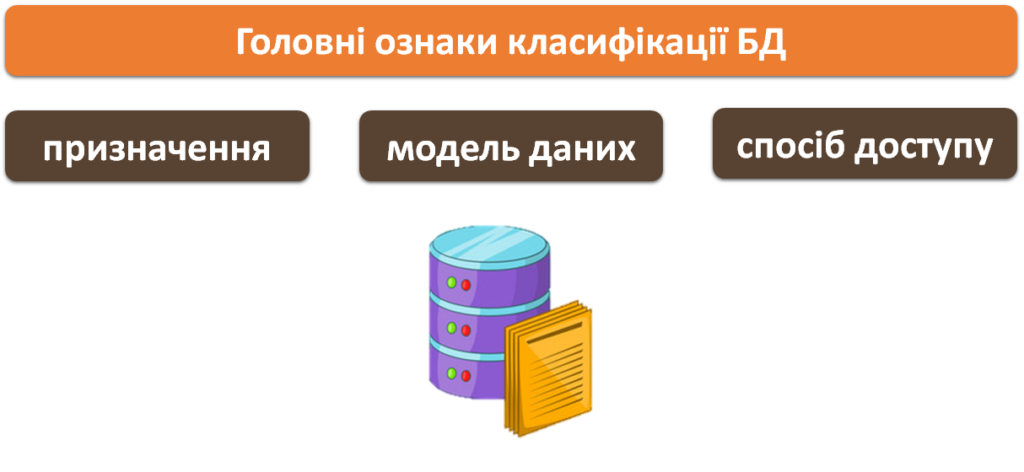
ІІ. Опрацюйте теоретичний матеріал (законспектуйте в зошити основні поняття та терміни):
База даних набуває цінності в складі інформаційної системи (ІС) та є однією з найважливіших її складових. Поняття інформаційної системи доволі об’ємне, тому однозначного її тлумачення не існує. Сьогодні ми спробуємо розібратися в ІС.





Розглянемо стисло сутність інформаційних систем, які функціонують у локальних комп’ютерних мережах.
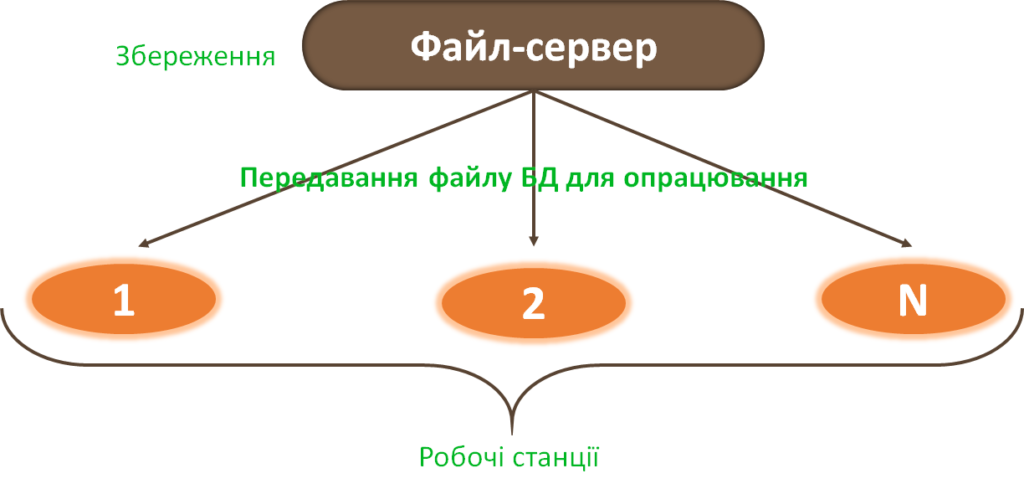
Централізована БД у цій архітектурі зберігається на комп’ютері-сервері. З робочих станцій (із комп’ютерів-клієнтів) посилаються запити на комп’ютер-сервер. У ньому відшукуються відповідні дані й у вигляді файлів без їх опрацювання пересилаються на робочі станції.
Опрацювання цих файлів здійснюється на робочих станціях. Файл-серверна архітектура потребує пересилання мережею великих, часто надлишкових обсягів даних, що є її недоліком. Окрім того, робочі станції повинні мати підвищену потужність для опрацювання отриманих даних.
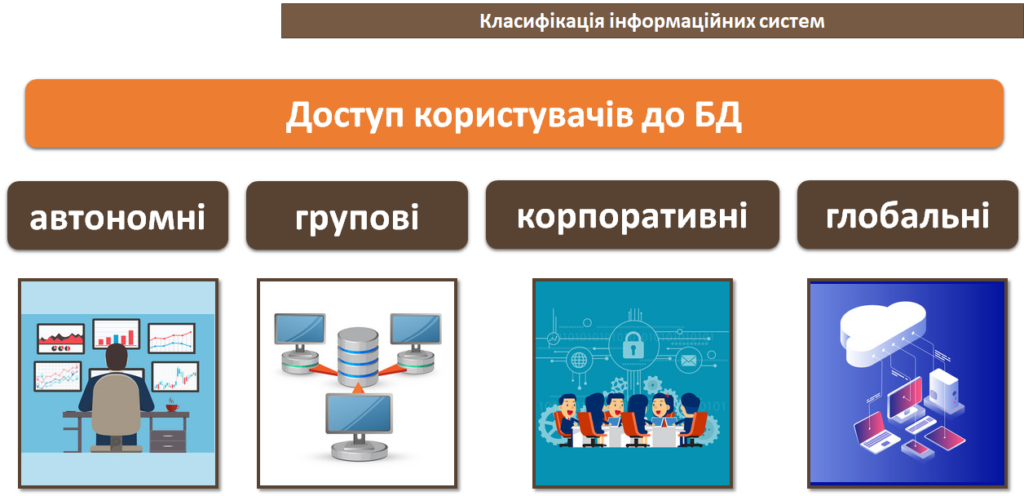
Зрозуміло, що на робочих станціях можуть зберігатися й персональні (автономні) бази даних для кожного клієнта.
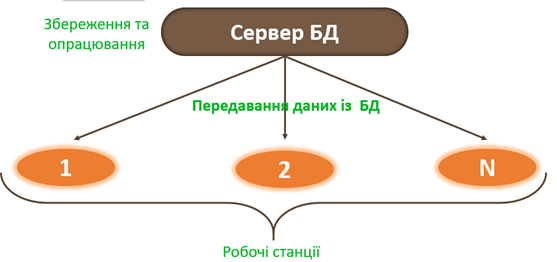
У клієнт-серверній архітектурі централізована БД також зберігається на комп’ютері-сервері. Персональні бази даних, як і в попередній архітектурі, також можуть зберігатися на робочих станціях. У відповідь на запити, що надходять із робочих станцій на комп’ютер-сервер, у ньому відшукуються необхідні дані та опрацьовуються за певним алгоритмом.
Опрацьовані дані передаються на робочі станції не у вигляді файлів даних, а як окремі записи, що суттєво знижує навантаження на локальну мережу.
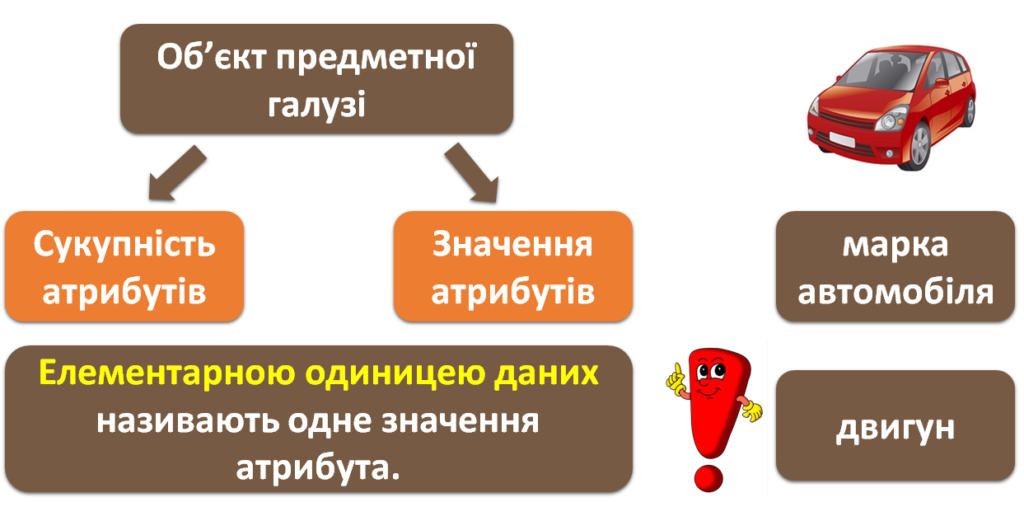
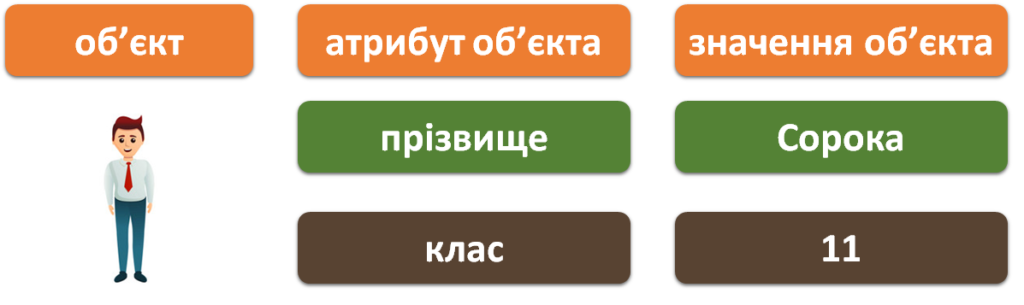
На минулому уроці вже було зазначено, що об’єкти предметної галузі характеризуються сукупністю атрибутів (властивостей) та їх значеннями. Одне значення атрибута називають елементарною одиницею даних. Наприклад, для об’єкта АВТОМОБІЛЬ його елементарними одиницями можуть бути марка — Volkswagen і двигун — дизельний.
Таким чином, об’єкти БД характеризуються сукупністю елементарних одиниць даних, між якими повинні бути встановлені однозначні зв’язки. Це означає, що основою будь-якої структури даних є відображення елементарної одиниці даних у вигляді трійки: <об’єкт, атрибут об’єкта, значення атрибута>, наприклад: <учень, прізвище, Сорока>; <учень, клас, 11>.

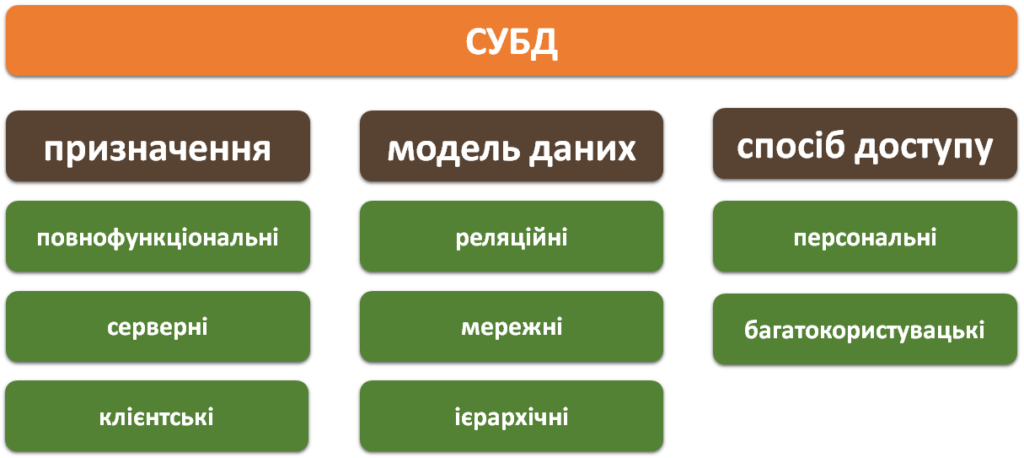
Існують різні способи відображення зв’язків між даними, тобто різні моделі даних. Нині є три класичні моделі даних: ієрархічна, мережева і реляційна. Розвиваються й інші моделі, що засновані на класичних, наприклад об’єктно-реляційна модель даних.
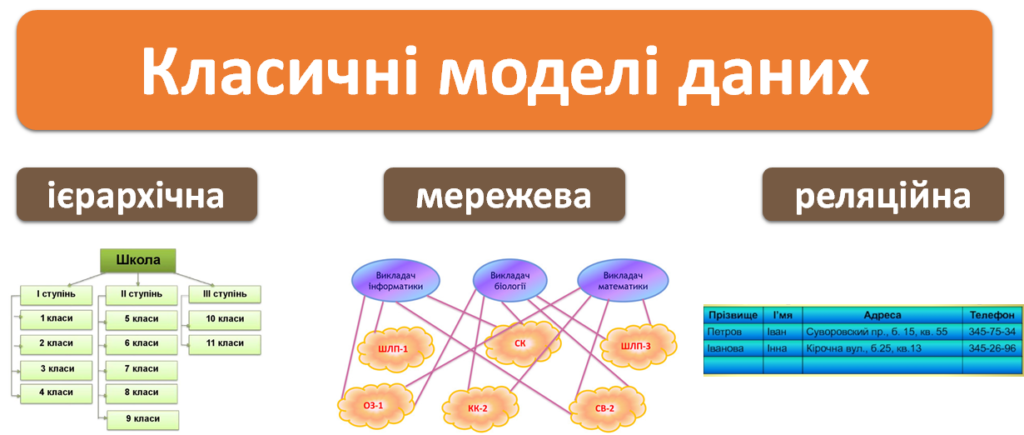

Ієрархічна і мережева моделі засновані на таких поняттях, як рівень, вузол, зв’язок.

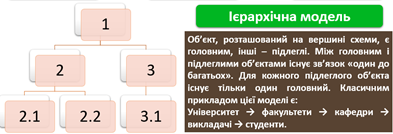
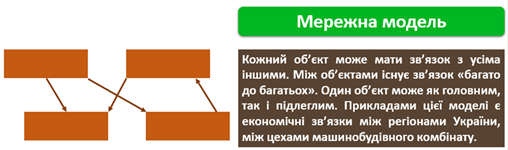
Основним недоліком ієрархічних і мережевих БД є складність їх розроблення, тому нині поширення набула реляційна модель даних — фактографічна база даних, що є набором взаємопов’язаних таблиць. Її основна перевага полягає у простоті розроблення БД і систем управління ними.

Зверніть увагу, що не кожна таблиця може бути об’єктом БД. Щоб таблиця була об’єктом БД, необхідно виконати нормалізацію. Сутність нормалізації полягає в тому, що таблиця має бути перетворена так, щоб вона відповідала основним вимогам:


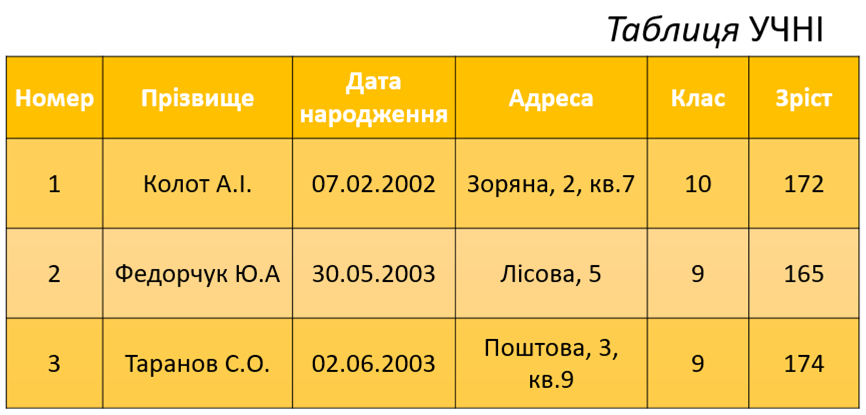
У таблиці може бути кілька ключів, але тільки один із них може бути первинним. Найкраще первинним ключем вибирати простий ключ. Бажано, щоб він мав цілочисловий тип. У такому випадку операції опрацювання даних виконуватимуться швидше. У таблиці УЧНІ простим полем є поле із іменем Номер.
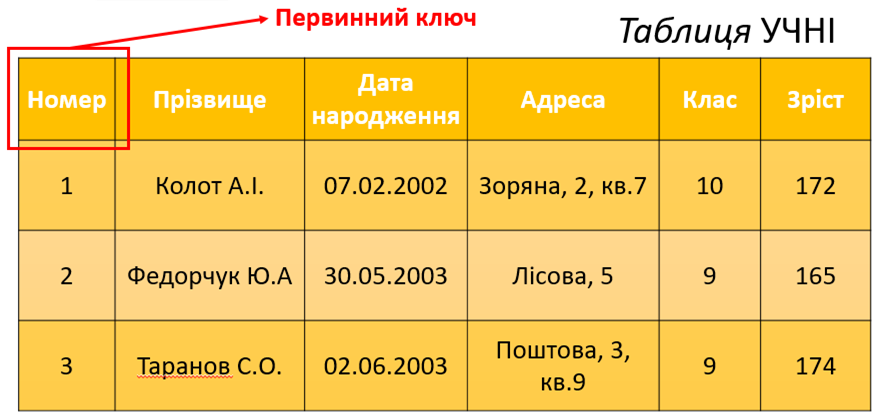
У таблиці часто використовують поле, яке називають лічильником. Він використовується для того, щоб зробити кожний запис унікальним. Окрім того, лічильник забезпечує нумерацію записів. Лічильником у таблиці УЧНІ є поле із іменем Номер.
Важливо усвідомити, що БД будь-якої складності можна створити на основі однієї таблиці. Але в такому випадку таблиця може містити сотні полів і тисячі записів. Розібратись і працювати з такою таблицею досить складно. Крім того, це може призвести до значного дублювання даних. Тому для кожного об’єкта розробляється власна таблиця. А щоб можна було одночасно отримати дані з кількох таблиць, слід установити зв’язки між ними.
Наприклад, для БД фірми в одній таблиці можуть зберігатися дані про співробітників фірми, у другій – дані про їх заробітну платню, у терті – відомості про постачальників продукції. Такий підхід спрощує подальшу модифікацію БД і має низку інших переваг.
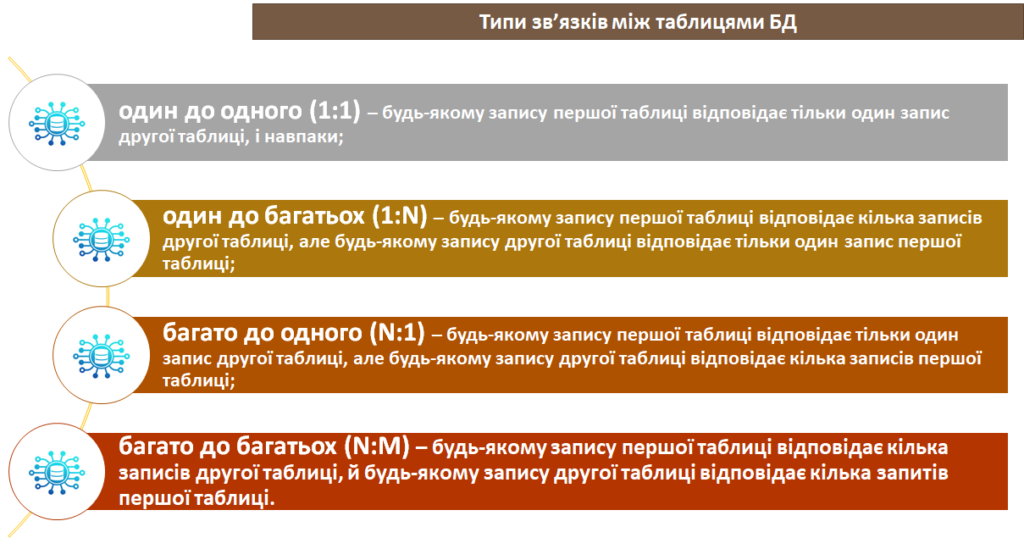
Зв’язки можуть установлювати між двома, трьома й більшою кількістю таблиць.
Для встановлення зв’язків між двома таблицями одна із них вважається основною (батьківською), а друга – допоміжною (дочірньою). В основній таблиці вибирають первинний ключ, а в допоміжній – зовнішній ключ.
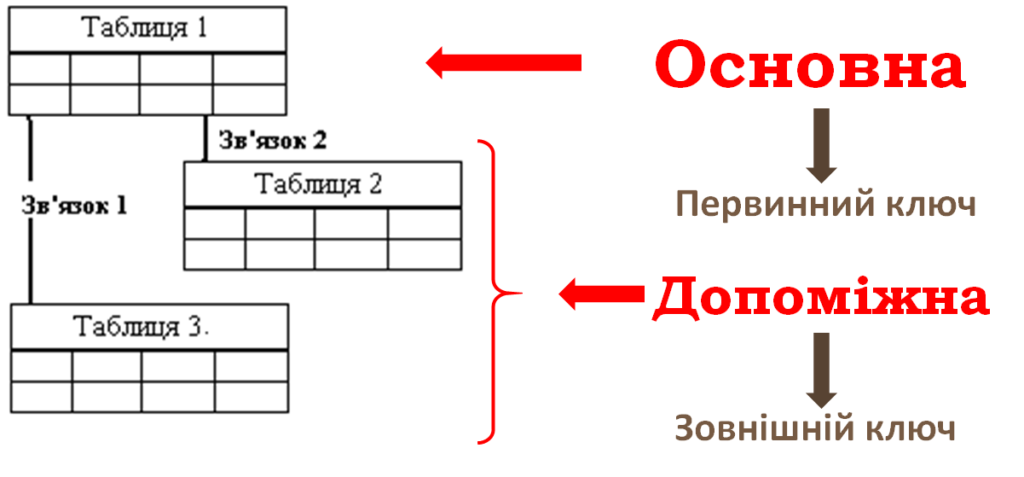
Головна вимога до зовнішнього ключа така: у ньому не може бути даних, відсутніх у первинному ключі, інакше зв’язок буде некоректним. Але часто зовнішній ключ вибирають із тим самим іменем, що й первинний ключ основної таблиці. Часто для забезпечення зв’язку між таблицями в допоміжну таблицю спеціально вводять поле із таким самим іменем, що й ім’я первинного ключа основної таблиці. У такому випадку деякі СУБД автоматично встановлюють зв’язок між цими таблицями. Якщо ж імена вказаних полів різні, користувач має сам установити зв’язок між ними.

Розглянемо на прикладі сутність зв’язків між двома таблицями. У БД будівельної компанії є дві таблиці – ПОСТАЧАЛЬНИКИ і ТОВАРИ.
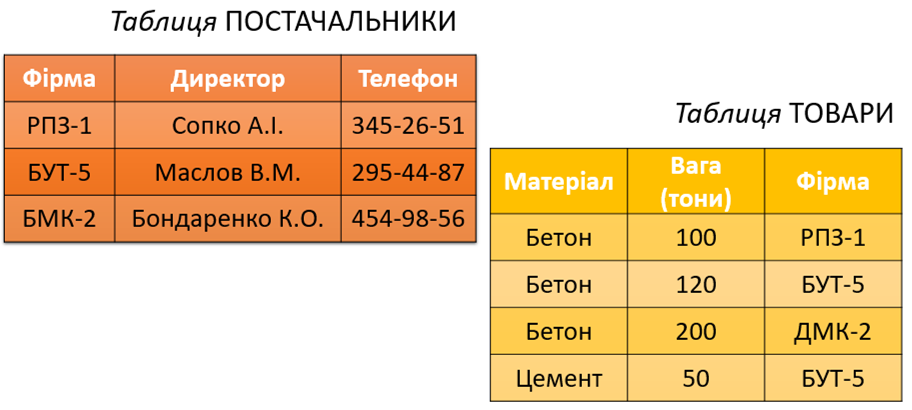
У таблиці ПОСТАЧАЛЬНИКИ первинним ключем є поле з іменем Фірма. У таблиці ТОВАРИ поле із цим іменем не може бути первинним ключем, бо в нього повторюються назви фірм, але воно може бути зовнішнім ключем, оскільки його значення збігаються зі значеннями однойменного поля таблиці ПОСТАЧАЛЬНИКИ. Більше того, вони мають однакове ім’я. За даними цього поля можна встановити зв’язок між таблицями ПОСТАЧАЛЬНИКИ й ТОВАРИ. Якщо потрібно дізнатися телефон і прізвища директора фірми, яка поставляє 120 т бетону і 50 т цементу, то слід із таблиці ТОВАРИ вибрати назву фірми БУТ-5 і за її назвою в таблиці ПОСТАЧАЛЬНИКИ знайти прізвище Маслов В.М., телефон 295-44-87. Таким чином, зв’язки між таблицями дають змогу отримати дані з кількох таблиць. Окрім того, вони забезпечують цілісність даних у пов’язаних таблицях, якщо з деяких причин сталися зміни в одній таблиці.
Розглянемо сутність цілісності даних на прикладі вже розглянутих раніше таблиць. Припустимо, що між табл. ПОСТАЧАЛЬНИКИ і ТОВАРИ зв’язок не встановлено, з таблиці ПОСТАЧАЛЬНИКИ видалено запис, де директором фірми є Маслов В.М., а в таблиці ТОВАРИ усі дані є цілісними. Ця ситуація відображена в таблиці, на наступному рисунку:
У такому випадку стає невідомий телефон і прізвище директора фірми БУТ-5, яка постачає 120 т бетону і 50 т цементу. Вважається, що в такому випадку сталося порушення цілісності даних і ця ситуація має бути автоматично виявлена.